免费的大模型长文本来了(2)
参数量剧增所带来的好处自然是大模型对于更长的内容拥有更快速的理解能力,这能够帮助用户从中提炼到所需的摘要、信息点,又或是直接生成整篇内容的总结。语言大模型之所以能够快速「引爆」整个市场,正是得益于这种速度惊人的理解能力。
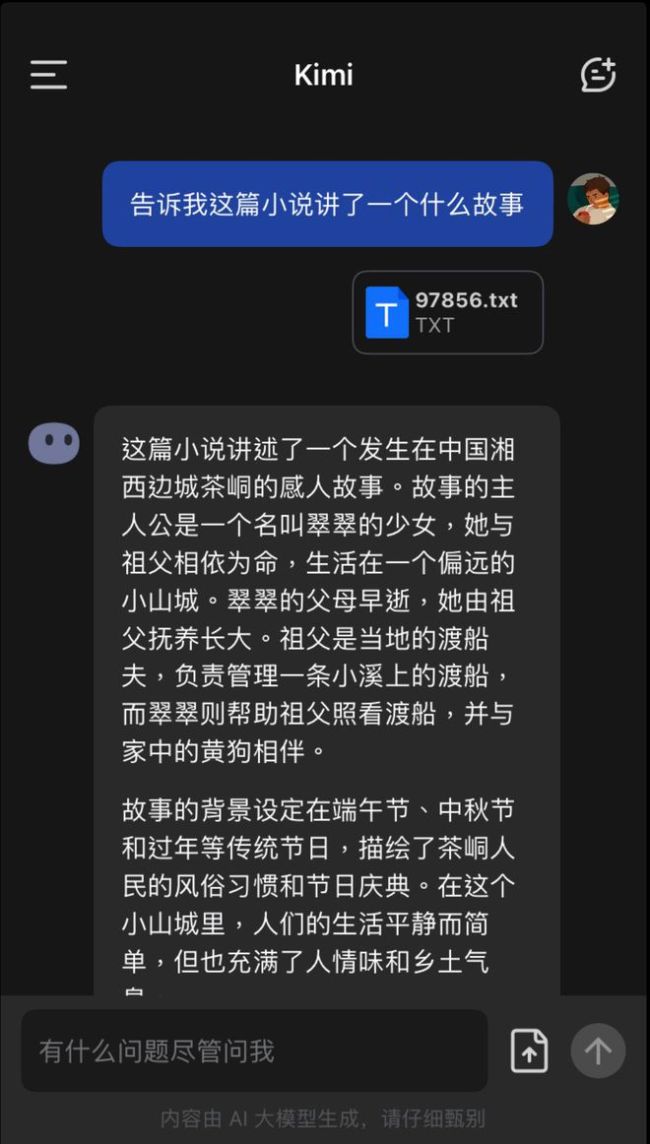
(图源:雷科技制图/Kimi Chat)
但要彻底攻克长文本,大模型光靠堆砌token参数量并不能完全解决这个问题。超大数量的token的确能够快速阅读完长文档,但段落与段落间的内容也更容易出现「断裂」的情况,这与缺少模型的预先训练有关。目前拥有超大token的AI方案提供商,通常在Transformer预测词之前投喂词元模型,使整体结论更加完整。

(图源:Code-Llama)
比如Code-Llama,标称16K token参数量,但实际上是由一个个4K token窗口连接而成,最终产生出16k token总模型。而这就十分考验大模型工具在窗口之间的推理能力。试想一下,在专业领域中,长文内容都有紧密的逻辑性与关联性,假如大模型推理失误,则有可能出现最终生成的摘要牛头不对马嘴,这对于大模型工具的商业、个人应用,都是致命的打击。
当然,大模型的推理能力是可以通过训练得到进步的,这就不难解释为何阿里、百度都选择优先将长文本模型功能免费开放给个人用户,毕竟更多用户加入,模型推理能力的进化速度才能加快。
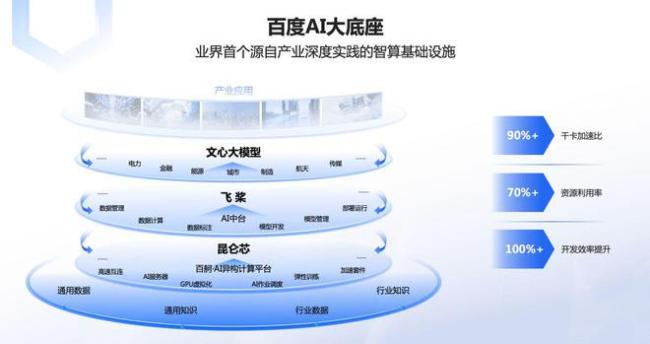
(图源:百度文心一言)
热点推送
-

唐源电气:前三季度机器视觉智能检测装备等核心主业收入稳健增长
上证报中国 网讯(记者张问之)10月29日晚, 唐源电气 披露三季报
2025-10-30唐源电气,智能检测,机器视觉 -
安克创新:拟2.29亿元收购子公司海翼智新4.27%股份
安克创新10月29日公告,公司拟以现金方式向南京海翼远致管理咨询合伙企业(有限合伙)(曾用名:天津海翼远扬管理咨询合伙企业(有限合伙))收购控股子公司海翼智新4.2659%的股权,海翼远致将在本次收购完成后进行相应减资
2025-10-30安克创新,管理咨询,有限合伙 -
三六零旗下公司以1.32亿元中标武汉AI基地项目
中证报中证网讯(记者任明杰)10月28日,武汉人工智能创新应用示范基地项目(一期)中标结果正式公布,三六零旗下的三六零数字安全科技集团有限公司以1.32亿元成功中标。这也是继本月中标呼和浩特项目之后,三六零拿下的又一个亿元级订单
2025-10-30人工智能,安徽,AI -
鱼跃医疗三季报公布,海外市场高速增长
近日,家用呼吸机龙头鱼跃医疗(002223.SZ)发布三季报
2025-10-30鱼跃医疗,公司,市场 -
贵州茅台第三季度净利、营收增速均放缓至不足1%,前三季度系列酒收入下滑
贵州茅台前三季度日均赚2.37亿元,但总营收和净利润增速均创下自2015年以来新低
2025-10-30贵州茅台,同比,增长 -
掌趣科技:前三季度实现营收5.34亿元
中证报中证网讯(王珞)10月29日,掌趣科技发布2025年第三季度报告
2025-10-30掌趣科技,公司,游戏行业 -
均胜电子营收净利双增长 前三季度新获订单约714亿元
中证报中证网讯(王珞)10月29日,均胜电子发布2025年第三季度报告,不仅营业收入同比双位数增长,盈利水平也保持快速增长趋势,并在汽车智能化等新兴业务领域实现多点突破,打造新增长引擎
2025-10-30均胜电子,汽车,公司 -
TCL智家:第三季度净利润3.39亿元 同比增长27.51%
TCL智家公告,2025年第三季度营收为48.69亿元,同比下降2.30%;净利润为3.39亿元,同比增长27.51%。前三季度营收为143.46亿元,同比增长2.87%;净利润为9.77亿元,同比增长18.45%
2025-10-30同比,净利润,亿元 -
盛邦安全:前三季度营收同比增长8.49% 研发投入同比增长22.98%
中证报中证网讯(王珞)10月29日,盛邦安全发布2025年第三季度报告,公司前三季度实现营业收入15535.02万元,同比增长8.49%,研发投入6665万元,同比增长22.98%
2025-10-30盛邦安全,网络安全,加密 -
宏景科技:前三季度净利润1.08亿元 同比增长448.91%
人民财讯10月29日电,宏景科技(301396)10月29日发布2025年三季报,公司第三季度营业收入3.63亿元,同比增长707.72%;净利润4723.77万元,同比增长323.01%
2025-10-30同比,净利润,亿元 -
利亚德第三季度归母净利润为1.07亿元,同比上升101.1%
10月29日,利亚德(300296)公布2025年三季报,公司营业收入为53.0亿元,同比下降3.0%;归母净利润为2.79亿元,同比上升53.7%;扣非归母净利润为2.32亿元,同比上升66.0%;经营现金流净额为5.79亿元
2025-10-30公司,同比,亿元 -
细胞产品业务显著增长 奥浦迈第三季度实现归母净利润同比大增283.59%
上证报中国 10月29日晚发布2025年第三季度业绩报告,本报告期公司实现营收9378万元,同比增幅29.8%,实现归母净利润1188万元,同比大增283.59%,基本每股收益0.1元
2025-10-30公司,同比,亿元 -
江河集团第三季度归母净利润增长17.28% 社保基金现身股东榜
上证报中国 网讯 江河集团 10月29日发布2025年三季报。公司第三季度单季度实现营收52.15亿元,较上年同期下降5.22%;前三季度累计实现营收145.54亿元,同比下降5.63%
2025-10-30公司,同比,亿元 -
中金公司前三季度净利翻番,第三季度同比增加254.93%
中国国际金融股份有限公司(下称“中金公司”,601995.SH,3908.HK)前三季度净利润增长翻番
2025-10-30中金公司,负责人,管理部 -
瑞斯康达第三季度亏损额减少至489万元
10月29日,瑞斯康达(603803)公布2025年三季报,公司营业收入为8.46亿元,同比下降17.9%;归母净利润自去年同期亏损6504万元变为亏损4709万元
2025-10-30公司,同比,亿元 -
拓新药业:内蒙古设立全资子公司 推动公司整体发展战略落地
中证报中证网讯(王珞)10月28日晚,拓新药业发布关于对外投资设立子公司拓新药业(内蒙古)有限公司的公告
2025-10-30内蒙古,拓新药业,公司 -
盛邦安全前三季度亏损5407万元
10月29日,盛邦安全(688651)公布2025年三季报,公司营业收入为1.55亿元,同比上升8.5%;归母净利润自去年同期亏损3485万元变为亏损5407万元
2025-10-30公司,同比,亿元 -
苏农银行:2025年前三季净利润17.08亿元,同比增长5.01%
人民财讯10月29日电,苏农银行(603323)10月29日发布2025年第三季度报告显示,该行前三季度实现营业收入32.21亿元,同比增长0.08%;归属于母公司股东的净利润17.08亿元,同比增长5.01%
2025-10-30苏农银行,同比,增长 -
掌趣科技第三季度归母净利润为2877万元,同比下降49.6%
10月29日,掌趣科技(300315)公布2025年三季报,公司营业收入为5.34亿元,同比下降17.9%;归母净利润为7656万元,同比下降60.9%;扣非归母净利润为7566万元,同比下降54.0%;经营现金流净额为-646万元
2025-10-30公司,同比,亿元 -
安泰集团:2025年前三季度净利润同比减亏1.45亿元
中证智能财讯安泰集团(600408)10月30日披露2025年第三季度报告
2025-10-30公司,同比,亿元 -
隆平高科:2025年前三季度实现营业总收入28.41亿元
中证智能财讯隆平高科(000998)10月30日披露2025年第三季度报告
2025-10-30公司,本次,项目 -
悦康药业:2025年前三季度实现营业总收入17.59亿元
中证智能财讯悦康药业(688658)10月30日披露2025年第三季度报告
2025-10-30公司,三季度,百分点 -
华电能源:2025年前三季度净利润2.67亿元
中证智能财讯华电能源(600726)10月30日披露2025年第三季度报告
2025-10-30公司,三季度,百分点 -
天禾股份:2025年前三季度净利润3525.48万元 同比增长234.89%
中证智能财讯天禾股份(002999)10月30日披露2025年第三季度报告
2025-10-30公司,本次,项目 -
北特科技:2025年前三季度净利润9266.98万元 同比增长52.39%
中证智能财讯北特科技(603009)10月30日披露2025年第三季度报告
2025-10-30公司,三季度,百分点 -
天地在线:2025年前三季度实现营业总收入9.07亿元
中证智能财讯天地在线(002995)10月29日披露2025年第三季度报告
2025-10-30公司,三季度,百分点 -
晶赛科技:2025年前三季度净利润795.94万元 同比下降6.39%
中证智能财讯晶赛科技(920981)10月29日披露2025年第三季度报告
2025-10-30公司,三季度,百分点 -
井松智能:2025年前三季度净利润806.9万元
中证智能财讯井松智能(688251)10月30日披露2025年第三季度报告
2025-10-30公司,三季度,百分点 -
振德医疗:2025年前三季度净利润2.03亿元
中证智能财讯振德医疗(603301)10月30日披露2025年第三季度报告
2025-10-30公司,三季度,百分点 -
华软科技:2025年前三季度实现营业总收入2.61亿元
中证智能财讯华软科技(002453)10月30日披露2025年第三季度报告
2025-10-30公司,三季度,百分点