OpenAI CEO萨姆・阿尔特曼回应版权争议:AI不用新闻出版商提供训练数据
最近,OpenAI首席执行官萨姆・阿尔特曼在达沃斯世界经济论坛年会上回应了《纽约时报》等新闻出版商针对版权材料使用的指控。他明确表示,OpenAI开发的人工智能技术并不依赖于新闻出版商提供的大量训练数据。阿尔特曼还强调,公司的研究重点在于如何从少量、高质量的数据中获取更多信息。
“有些人认为,“你需要我所有的数据进行训练,我的数据非常有价值。”事实上,情况一般并非如此,例如我们并不想利用《纽约时报》的数据进行训练。”

这一声明是对《纽约时报》起诉OpenAI和微软一案的回应。OpenAI正在积极推动与新闻内容提供者之间的访问许可协议。据彭博社报道,OpenAI正在与CNN、福克斯公司和时代周刊等出版商商讨新闻内容授权事宜,并已有数十项潜在的授权交易正在进行中。
阿尔特曼在论坛上透露了自己希望与出版商合作的意愿,表示如果出版商愿意,他们希望能与之合作,例如在用户询问“今天达沃斯发生了什么”时,应用程序可以提供来自彭博社或《纽约时报》等来源的文章。他指出,虽然有些出版商愿意合作,但也有些不愿意。
这一表态不仅阐述了OpenAI在版权问题上的立场,也表明了公司在合法使用内容上的努力,以及其与内容提供者建立合作关系的意图。随着人工智能技术的发展,版权和内容使用的议题变得日益重要,OpenAI的这一举措可能为未来AI领域的版权管理树立了新的标杆。
热点推送
-

2026全新启程|第十三届PropertyGuru亚洲不动产奖中国区正式开放申报
泰国,曼谷 — 2026年第十三届PropertyGuru亚洲不动产奖(中国内地、中国香港和中国澳门)已正式启动,并推出扩展后的奖项类别,旨在表彰在可持续发展、健康宜居、智能科技、
2026-06-242026全新启程|第十三届PropertyGuru亚洲不动产奖中国区正式开放申报 -
星驿付与慧徕店亮相2026中国国际金融展,携手网联清算公司共建智慧场景生态,共绘数智民生图景
六月申城,浦江潮涌,由中国人民银行指导,上海市委、市政府支持,中国金融电子化集团有限公司主办的2026中国国际金融展,于6月16日至18日在上海世博展览馆隆重举行。
2026-06-23星驿付与慧徕店亮相2026中国国际金融展,携手网联清算公司共建智慧场景生态,共绘数智民生图景 -
日销近70吨!一颗大™沈阳曲牌开柜仪式圆满举行,引爆东北批发市场
近日,水果番茄品牌一颗大™联合核心经销商沈阳曲牌,在沈阳地利水果批发市场隆重举办夏季主题路演暨开柜仪式活动。
2026-06-18日销近70吨!一颗大™沈阳曲牌开柜仪式圆满举行,引爆东北批发市场 -
经纬蚂蚁等一线基金齐加注,世界模型公司逆矩阵完成超亿美元种子++轮融资
近日,逆矩阵科技(Physis)完成超亿美元种子++轮融资。
2026-06-18经纬蚂蚁等一线基金齐加注,世界模型公司逆矩阵完成超亿美元种子++轮融资 -
当供给侧AI走向同质化竞争,特赞的战略布局是需求侧突破
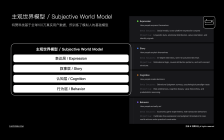
特赞科技Tezign 近期正式发布「主观世界模型」(Subjective World Model,SWM),将其定位为企业AI竞争进入下半程后的战略回应:当供给侧工具能力趋于同质
2026-06-16当供给侧AI走向同质化竞争,特赞的战略布局是需求侧突破 -
MedSeek.Ai赋能医疗险:良医汇迈出专业医疗AI与保险融合的第一步
2026年6月12日,"医疗保险智能体时代:英仕健康×良医汇 双AI引擎联合启动会"在上海陆家嘴举行。
2026-06-16MedSeek.Ai赋能医疗险:良医汇迈出专业医疗AI与保险融合的第一步 -
Babycare 618品质溯源:一条"延长线"背后的品质承诺
近日,上海、杭州部分人流密集的地铁通道里,一条特殊的“延长线”吸引了人们的目光。
2026-06-16Babycare 618品质溯源:一条延长线背后的品质承诺 -
校企联合铸精品 中建中环辐射致冷涂料拓宽绿色市场
在节能降碳成为产业发展主流方向的当下,零能耗绿色新材料迎来广阔的发展空间。
2026-06-15校企联合铸精品 中建中环辐射致冷涂料拓宽绿色市场 -
Snow Peak大力布局中国市场 与比音勒芬战略携手
2026年6月12日,比音勒芬集团(以下简称比音勒芬)举行了Snow Peak签约仪式,与Snow Peak, Inc. 、GAMSUNG达成战略合作
2026-06-13Snow Peak大力布局中国市场 与比音勒芬战略携手 -
华美月饼搭建“非遗共创”全民舞台 向世界讲好“中国传统文化”
华美月饼搭建“非遗共创”全民舞台向世界讲好“中国传统文化”2026年6月9日,华美食品集团在东莞总部举办35周年庆典暨2026中秋月饼营销峰会。
2026-06-12华美月饼搭建“非遗共创”全民舞台 向世界讲好“中国传统文化” -
月销突破200万!一颗大™X比优特路演活动燃动东三省
近日,水果番茄品牌一颗大™联合东北区域龙头商超比优特超市,在黑龙江、吉林、辽宁三省同步开展一颗大™×比优特夏季主题路演活动,活动覆盖比优特超市7家核心门店,现场人气火爆、下单率高
2026-06-09月销突破200万!一颗大™X比优特路演活动燃动东三省 -
厚植阳光信贷文化 赋能三秦高质量发展——邮储银行陕西省分行以清风正气护航金融惠民路
金融为民守初心,阳光信贷润三秦。
2026-06-08厚植阳光信贷文化 赋能三秦高质量发展——邮储银行陕西省分行以清风正气护航金融惠民路 -
再度加冕!MOVA吸尘器包揽伦敦、TITAN设计奖双国际顶级荣誉
继斩获德国红点、美国缪斯、纽约设计等三项大奖后,全球高端智能清洁品牌MOVA再度闪耀全球设计殿堂。
2026-06-02再度加冕!MOVA吸尘器包揽伦敦、TITAN设计奖双国际顶级荣誉 -
守好每一份托付,就是最大的责任——平安产险发布《2025年度企业社会责任报告》
在经济社会高质量发展的时代坐标下,企业社会责任早已超越简单捐赠的传统范畴,成为衡量一家企业核心竞争力与可持续发展能力的重要维度。
2026-06-01守好每一份托付,就是最大的责任——平安产险发布《2025年度企业社会责任报告》 -
2026仅三生物·玻麦妍美白系列全球首发,以科学定义美白新标准
GeneIII仅三生物·玻麦妍美白发光节圆满落幕,Frost&Sullivan沙利文《全球麦角硫因行业现状与发展趋势》重磅首发!2026年5月18日
2026-06-012026仅三生物·玻麦妍美白系列全球首发,以科学定义美白新标准 -
大商集团新加坡FHA展&上海西雅展,双展收官
近日,2026新加坡FHA国际食品与酒店展(4.21-4.24)与2026上海西雅国际食品饮料展(5.18-5.20)相继落下帷幕。
2026-05-28大商集团新加坡FHA展&上海西雅展,双展收官 -
商聚王佐・协创未来暨2026王佐镇倍增追赶合作发展大会圆满举行
5月26日,“商聚王佐・协创未来”暨2026王佐镇倍增追赶合作发展大会在北京南宫泉都酒店成功举办。
2026-05-27商聚王佐・协创未来暨2026王佐镇倍增追赶合作发展大会圆满举行 -
2026年精品天然湖盐品牌测评:品质生活厨房选什么盐有格调
对于追求品质生活的人而言,盐罐里的盐同样讲究产区、工艺和视觉质感。
2026-05-262026年精品天然湖盐品牌测评:品质生活厨房选什么盐有格调 -
2026北京楼市回暖提质 禧悦兴城凭硬核兑现力领跑刚需赛道
今年以来,北京房地产市场呈现稳步回暖态势。
2026-05-252026北京楼市回暖提质 禧悦兴城凭硬核兑现力领跑刚需赛道 -
不同集团释放AI产品升级信号:走向家庭物理AI应用新生态
AI走向物理世界,家庭生活成为新入口当AI产业从模型、算力和内容生成,进一步走向场景应用,一个新的关键词正在被市场频繁提起:物理AI。
2026-05-25不同集团释放AI产品升级信号:走向家庭物理AI应用新生态 -
东方美学复兴下的品牌机遇:紫川珠宝的出海想象
当《原神》的游戏场景让全球玩家沉醉于璃月港的山水意境,当“新中式”服饰成为巴黎时装周的焦点
2026-05-25东方美学复兴下的品牌机遇:紫川珠宝的出海想象 -
乔山Welltivity公益支持全国助残日活动,以运动赋能残健融合
2026年5月18日上午,杭州上城区西子国际中心暖意融融,由上城区残联、四季青街道办事处、新华保险浙江分公司联合主办的“‘特有爱・新’益路同行”主题公益活动温情启幕。
2026-05-22乔山Welltivity公益支持全国助残日活动,以运动赋能残健融合 -
麦德龙自有品牌再摘PLMA大奖:以差异化“商品力”推动中国零售品质走向世界
在全球批发零售业,自有品牌早已不是“平替”的代名词。
2026-05-22麦德龙自有品牌再摘PLMA大奖:以差异化“商品力”推动中国零售品质走向世界 -
不同集团:一个被“婴儿推车”标签遮住的AI家庭消费公司
只看名字,你可能会把不同集团(6090.HK)归入“母婴用品”这个略显拥挤的赛道。
2026-05-19不同集团:一个被“婴儿推车”标签遮住的AI家庭消费公司 -
极智跃迁,万店升维!沃庭科技智慧锂电工具“敢梦合伙人”全国招募正式启动
【2026年5月18日讯】随着中国高端制造持续向全球价值链上游迈进,专业电动工具行业也迎来新一轮智能化升级浪潮。
2026-05-19极智跃迁,万店升维!沃庭科技智慧锂电工具“敢梦合伙人”全国招募正式启动 -
林里LINLEE携手蔡徐坤,释放中国茶饮品牌化新信号
正文5月18日,全国头部现制手打柠檬茶品牌林里LINLEE正式宣布蔡徐坤成为林里全球品牌代言人。
2026-05-18林里LINLEE携手蔡徐坤,释放中国茶饮品牌化新信号 -
玖电科技荣膺“2026行业十大影响力品牌”奖,引领行业数字化发展
近日,2026第五届上海国际充换电与光储充展览会于上海汽车会展中心盛大启幕。
2026-05-15玖电科技荣膺“2026行业十大影响力品牌”奖,引领行业数字化发展 -
当咖啡机学会思考,一场无人零售的“咖啡革命”已经爆发
中国咖啡市场正经历从“人力密集型”向“AI驱动型”的跨越式转折。
2026-05-13当咖啡机学会思考,一场无人零售的“咖啡革命”已经爆发 -
盐池滩羊亮相莫干山品牌盛会 以“四好”底气书写地域品牌向新答卷
五月的德清,莫干山麓草坪如茵,清风裹挟着品牌的力量,汇聚成一场跨越山海的交流盛宴。
2026-05-13盐池滩羊亮相莫干山品牌盛会 以“四好”底气书写地域品牌向新答卷 -
成立不到半年 单月销售破千万!追觅健康生活版块强势突围 新业务线狂飙增长
2026年4月,追觅科技健康生活版块业务迎来里程碑式突破:单月业绩突破1000万元,产品上市仅3个月即实现爆发式增长,连续3个月环比增速超500%
2026-05-12成立不到半年 单月销售破千万!追觅健康生活版块强势突围 新业务线狂飙增长